Node IO stress
Node IO stress causes I/O stress on the Kubernetes node.
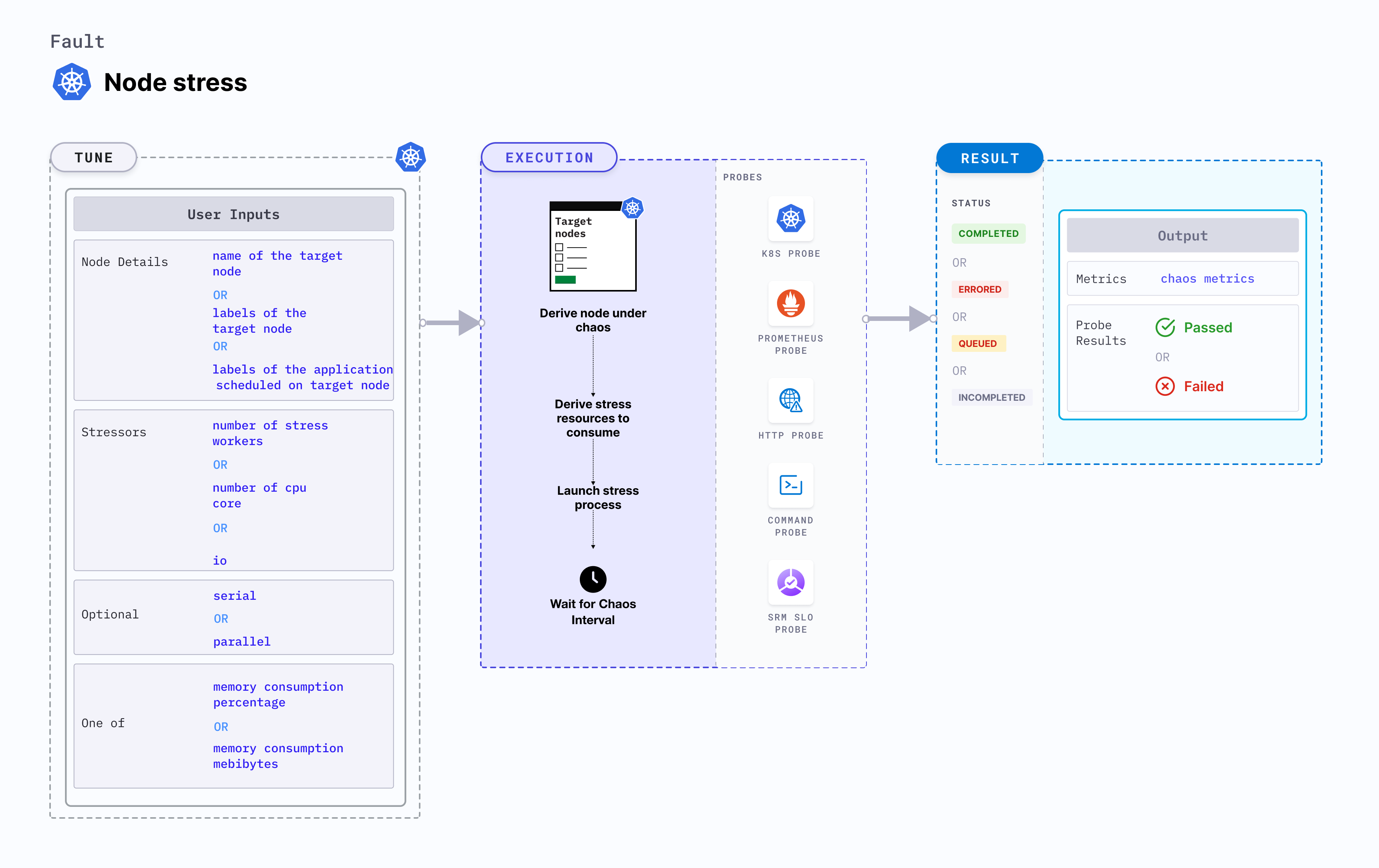
Use cases
- Node IO stress fault verifies the resilience of applications that share the disk resource for ephemeral or persistent storage during high disk I/O usage.
- It tests application resilience on replica evictions that occur due to I/O stress on the available disk space.
- It simulates slower disk operations by the application and noisy neighbour problems by hogging the disk bandwidth.
- It also verifies the disk performance on increasing I/O threads and varying I/O block sizes.
- It checks if the application functions under high disk latency conditions. when I/O traffic is very high and includes large I/O blocks, and when other services monopolize the I/O disks.
Permissions required
Below is a sample Kubernetes role that defines the permissions required to execute the fault.
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: hce
name: node-io-stress
spec:
definition:
scope: Cluster
permissions:
- apiGroups: [""]
resources: ["pods"]
verbs: ["create", "delete", "get", "list", "patch", "deletecollection", "update"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "get", "list", "patch", "update"]
- apiGroups: [""]
resources: ["chaosEngines", "chaosExperiments", "chaosResults"]
verbs: ["create", "delete", "get", "list", "patch", "update"]
- apiGroups: [""]
resources: ["pods/log"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["pods/exec"]
verbs: ["get", "list", "create"]
- apiGroups: ["batch"]
resources: ["jobs"]
verbs: ["create", "delete", "get", "list", "deletecollection"]
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list"]
Prerequisites
- Kubernetes > 1.16
- The target nodes should be in the ready state before and after injecting chaos.
Mandatory tunables
| Tunable | Description | Notes |
|---|---|---|
| TARGET_NODES | Comma-separated list of nodes subject to node I/O stress. | For example, node-1,node-2. For more information, go to target nodes. |
| NODE_LABEL | It contains the node label that is used to filter the target nodes. It is mutually exclusive with the TARGET_NODES environment variable. | If both the environment variables are provided, TARGET_NODES takes precedence. For more information, go to node label. |
Optional tunables
| Tunable | Description | Notes |
|---|---|---|
| TOTAL_CHAOS_DURATION | Duration that you specify, through which chaos is injected into the target resource (in seconds). | Default: 120 s. For more information, go to duration of the chaos. |
| FILESYSTEM_UTILIZATION_PERCENTAGE | Specify the size as a percentage of free space on the file system. | Default: 10 %. For more information, go to file system utilization percentage. |
| FILESYSTEM_UTILIZATION_BYTES | Specify the size of the files used per worker (in GB). FILESYSTEM_UTILIZATION_PERCENTAGE and FILESYSTEM_UTILIZATION_BYTES are mutually exclusive. | If both are provided, FILESYSTEM_UTILIZATION_PERCENTAGE takes precedence. For more information, go to file system utilization bytes. |
| CPU | Number of cores of the CPU that will be used. | Default: 1. For more information, go to CPU cores. |
| NUMBER_OF_WORKERS | Number of I/O workers involved in I/O stress. | Default: 4. For more information, go to workers for stress. |
| VM_WORKERS | Number of VM workers involved in I/O stress. | Default: 1. For more information, go to workers for stress. |
| LIB_IMAGE | Image used to run the stress command. | Default: chaosnative/chaos-go-runner:main-latest. For more information, go to image used by the helper pod. |
| RAMP_TIME | Period to wait before and after injecting chaos (in seconds). | For example, 30 s. For more information, go to ramp time. |
| NODES_AFFECTED_PERC | Percentage of the total nodes to target. It takes numeric values only. | Default: 0 (corresponds to 1 node). For more information, go to node affected percentage. |
| SEQUENCE | Sequence of chaos execution for multiple target pods. | Default: parallel. Supports serial sequence as well. For more information, go to sequence of chaos execution. |
File system utilization percentage
Free space available on the node (in percentage). Tune it by using the FILESYSTEM_UTILIZATION_PERCENTAGE environment variable.
The following YAML snippet illustrates the use of this environment variable:
# stress the I/O of the targeted node with FILESYSTEM_UTILIZATION_PERCENTAGE of total free space
# it is mutually exclusive with the FILESYSTEM_UTILIZATION_BYTES.
# if both are provided then it will use FILESYSTEM_UTILIZATION_PERCENTAGE for stress
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: litmus-admin
experiments:
- name: node-io-stress
spec:
components:
env:
# percentage of total free space of file system
- name: FILESYSTEM_UTILIZATION_PERCENTAGE
value: '10' # in percentage
- name: TOTAL_CHAOS_DURATION
VALUE: '60'
File system utilization bytes
Free space available on the node (in gigabytes). Tune it by using the FILESYSTEM_UTILIZATION_BYTES environment variable. It is mutually exclusive with the FILESYSTEM_UTILIZATION_PERCENTAGE environment variable. When both the values are provided, FILESYSTEM_UTILIZATION_PERCENTAGE takes precedence.
The following YAML snippet illustrates the use of this environment variable:
# stress the i/o of the targeted node with given FILESYSTEM_UTILIZATION_BYTES
# it is mutually exclusive with the FILESYSTEM_UTILIZATION_PERCENTAGE.
# if both are provided then it will use FILESYSTEM_UTILIZATION_PERCENTAGE for stress
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: litmus-admin
experiments:
- name: node-io-stress
spec:
components:
env:
# file system to be stress in GB
- name: FILESYSTEM_UTILIZATION_BYTES
value: '500' # in GB
- name: TOTAL_CHAOS_DURATION
VALUE: '60'
Limit CPU utilization
CPU usage limit while the CPU undergoes I/O stress. Tune it by using the CPU environment variable.
The following YAML snippet illustrates the use of this environment variable:
# limit the CPU uses to the provided value while performing io stress
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: litmus-admin
experiments:
- name: node-io-stress
spec:
components:
env:
# number of CPU cores to be stressed
- name: CPU
value: '1'
- name: TOTAL_CHAOS_DURATION
VALUE: '60'
Workers for stress
Number of I/O and VM workers for the stress. Tune it by using the NUMBER_OF_WORKERS and VM_WORKERS environment variables, respectively.
The following YAML snippet illustrates the use of this environment variable:
# define the workers count for the i/o and vm
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: litmus-admin
experiments:
- name: node-io-stress
spec:
components:
env:
# total number of io workers involved in stress
- name: NUMBER_OF_WORKERS
value: '4'
# total number of vm workers involved in stress
- name: VM_WORKERS
value: '1'
- name: TOTAL_CHAOS_DURATION
VALUE: '60'